soup查找tag,结果为空[]
问题描述:
为什么soup.select("img[width="160"]")结果是[]? 网址: http://www.tripadvisor.cn/Attractions-g60763-Activities-oa30-New_York_City_New_York.html#ATTRACTION_LIST
而我在开发者工具中,明明是有的呀? 如:
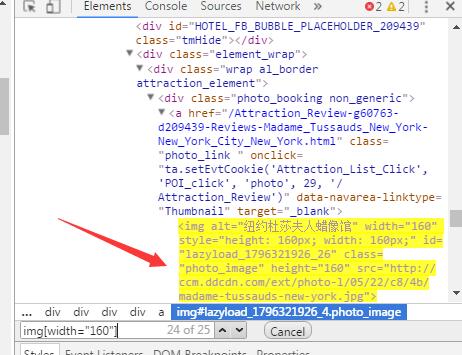
问题解决
首先你需要排除几个影响因素:
- 1、selector是否写对?
- 2、网页源码中是否含有我要找的内容?
- 3、在headers中加入Agent-User或者cookie是否有用?
- 4、伪装成手机浏览器是否有用?
- 5、加入Referer是否有用?
1、selector是否写对?
F12 打开我们的开发者工具,在Elements中Ctrl+F 把我们的selector复制进去,有找到我们想要的内容就说明selector是没错的,转问题2,否则,改一改selector。
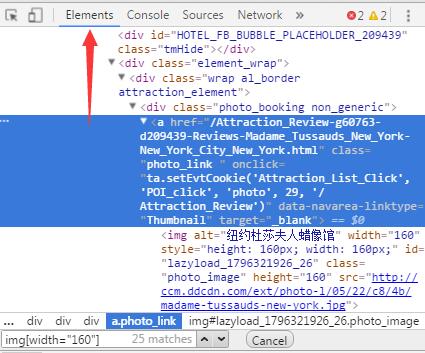
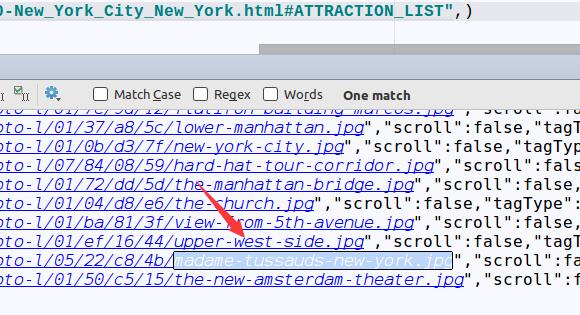
2、网页源码中是否含有我要找的内容?
将我们想要的内容复制,如:
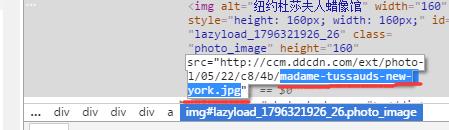
madame-tussauds-new-york.jpg
在浏览器网页上鼠标右键 查看网页源码,查找:
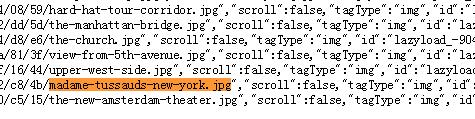
在源码中找到了我们想要的内容,但是却出现在了script中,我们没办法使用lxml正常解析。为什么没有出现在该出现的位置呢?因为这个数据是通过js脚本加到我们网页的主体内容上的。因为我们的程序是没有运行js脚本的,所以没办法使用正常的方法(select)获取。
尝试下问题3
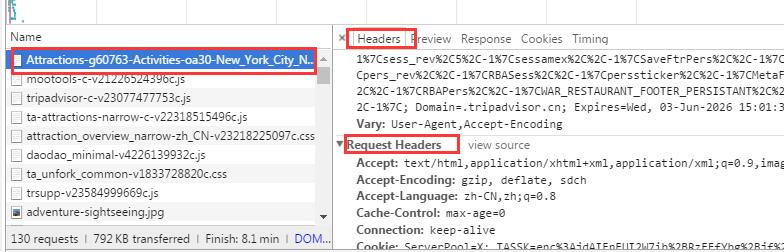
3、在headers中加入Agent-User或者cookie是否有用?
还是用我们的开发者工具,在network一栏中,找到Agent-User和cookie: 选择第一个查看requests headers:
这时我们就要用程序去尝试会更快,写好程序:
#coding:utf-8
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36',
'Cookie':'ServerPool=X; TASSK=enc%3AjdAIEnEUI2W7ib%2BRzEEfYbg%2Bjf%2FGJ2FeuxWecNuh1b9%2BG4uSJWL14%2BMwdNe1wynX; TAUnique=%1%enc%3AyptiXtNF4o6wsKQVc45OsHwVy9f4akSHVUbAcqKV9Fo2jHwltRJPGQ%3D%3D; TAPD=tripadvisor.cn; __gads=ID=f756d423c624c3a6:T=1465124473:S=ALNI_MYb2KIun9_Lx47a9fojaf8YSf05-Q; ki_t=1465124476104%3B1465124476104%3B1465124476104%3B1%3B1; ki_r=; MobileLastViewedList=%1%%2FAttractions-g60763-Activities-oa30-New_York_City_New_York.html; taMobileRV=%1%%7B%2210028%22%3A%5B60763%5D%7D; a5281_times=1; BD_vm133w=_; BD_vm133w=_; TATravelInfo=V2*A.2*MG.-1*HP.2*FL.3; roybatty=APh3S5oN23jNlA08aqSjGGadxhY2Yxug5ybfhzb2XdppHOY5EPoFXpmj4Vb3BBS322SG1lbxpTddueH2Z951T0Ul%2BAYR%2Fc4TKhu%2FtWM7xl%2BSg7mbdFgzOXTLQMFe5M4q4NSd%2BUDI9CYtjwQ50Ixpt8o8SBpRMEkcf45kII%2FcRRup%2C1; Hm_lvt_2947ca2c006be346c7a024ce1ad9c24a=1465124800; Hm_lpvt_2947ca2c006be346c7a024ce1ad9c24a=1465135673; a2117_pages=4; a2117_times=2; Hm_lvt_69d068dda1da018d9b4ba380c7b92ee3=1465124473; Hm_lpvt_69d068dda1da018d9b4ba380c7b92ee3=1465135673; NPID=; TASession=%1%V2ID.B273D66C4BEC744CE37CDD3CA404F787*SQ.14*LS.Attractions*GR.46*TCPAR.88*TBR.50*EXEX.38*ABTR.30*PPRP.51*PHTB.78*FS.10*CPU.76*HS.popularity*ES.popularity*AS.popularity*DS.5*SAS.popularity*FPS.oldFirst*FA.1*DF.0*LP.%2FLangRedirect%3Fauto%3D3%26origin%3Dzh%26pool%3DX%26returnTo%3D%252FAttractions-g60763-Activities-oa30-New_York_City_New_York%5C.html*IR.3*OD.zh*RT.0*FLO.60763*TRA.true*LD.60763; CM=%1%HanaPersist%2C%2C-1%7Ct4b-pc%2C%2C-1%7CHanaSession%2C%2C-1%7CFtrSess%2C%2C-1%7CRCPers%2C%2C-1%7CHomeAPers%2C%2C-1%7CWShadeSeen%2C%2C-1%7CRCSess%2C%2C-1%7CFtrPers%2C%2C-1%7CHomeASess%2C%2C-1%7Csh%2C%2C-1%7Cpssamex%2C%2C-1%7C2016sticksess%2C%2C-1%7CCCPers%2C%2C-1%7CCCSess%2C%2C-1%7CWAR_RESTAURANT_FOOTER_SESSION%2C%2C-1%7Cb2bmcsess%2C%2C-1%7Csesssticker%2C%2C-1%7C%24%2C%2C-1%7C2016stickpers%2C%2C-1%7Ct4b-sc%2C%2C-1%7CMC_IB_UPSELL_IB_LOGOS2%2C%2C-1%7Cb2bmcpers%2C%2C-1%7CMC_IB_UPSELL_IB_LOGOS%2C%2C-1%7Csess_rev%2C4%2C-1%7Csessamex%2C%2C-1%7CSaveFtrPers%2C%2C-1%7CSaveFtrSess%2C%2C-1%7Cpers_rev%2C%2C-1%7CRBASess%2C%2C-1%7Cperssticker%2C%2C-1%7CMetaFtrSess%2C%2C-1%7Cmds%2C%2C-1%7CRBAPers%2C%2C-1%7CWAR_RESTAURANT_FOOTER_PERSISTANT%2C%2C-1%7CMetaFtrPers%2C%2C-1%7C; TAUD=LA-1465124469834-1*LG-13046557-2.0.F*LD-13046559-.....; TAReturnTo=%1%%2FAttractions-g60763-Activities-oa30-New_York_City_New_York.html',
}
resp = requests.get("http://www.tripadvisor.cn/Attractions-g60763-Activities-oa30-New_York_City_New_York.html#ATTRACTION_LIST",headers=headers)
soup = BeautifulSoup(resp.text,"lxml")
print(soup)
在headers 中加入User-Agent、cookie等。 在得到的结果中,我们依然只是在script中找到我们想要的内容(可以将网页源码写入文件中,方便查看)。
尝试伪装成手机浏览器:
4、伪装成手机浏览器是否有用?
修改一下代码,把User-Agent改一下,改成iphone。怎么才会有iphone的User-Agent呢?课程视频中有详细解说,再此不再赘述。
headers = {
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1',
'Cookie':'ServerPool=X; TASSK=enc%3AjdAIEnEUI2W7ib%2BRzEEfYbg%2Bjf%2FGJ2FeuxWecNuh1b9%2BG4uSJWL14%2BMwdNe1wynX; TAUnique=%1%enc%3AyptiXtNF4o6wsKQVc45OsHwVy9f4akSHVUbAcqKV9Fo2jHwltRJPGQ%3D%3D; TAPD=tripadvisor.cn; __gads=ID=f756d423c624c3a6:T=1465124473:S=ALNI_MYb2KIun9_Lx47a9fojaf8YSf05-Q; ki_t=1465124476104%3B1465124476104%3B1465124476104%3B1%3B1; ki_r=; MobileLastViewedList=%1%%2FAttractions-g60763-Activities-oa30-New_York_City_New_York.html; taMobileRV=%1%%7B%2210028%22%3A%5B60763%5D%7D; a5281_times=1; BD_vm133w=_; BD_vm133w=_; TATravelInfo=V2*A.2*MG.-1*HP.2*FL.3; roybatty=APh3S5oN23jNlA08aqSjGGadxhY2Yxug5ybfhzb2XdppHOY5EPoFXpmj4Vb3BBS322SG1lbxpTddueH2Z951T0Ul%2BAYR%2Fc4TKhu%2FtWM7xl%2BSg7mbdFgzOXTLQMFe5M4q4NSd%2BUDI9CYtjwQ50Ixpt8o8SBpRMEkcf45kII%2FcRRup%2C1; Hm_lvt_2947ca2c006be346c7a024ce1ad9c24a=1465124800; Hm_lpvt_2947ca2c006be346c7a024ce1ad9c24a=1465135673; a2117_pages=4; a2117_times=2; Hm_lvt_69d068dda1da018d9b4ba380c7b92ee3=1465124473; Hm_lpvt_69d068dda1da018d9b4ba380c7b92ee3=1465135673; NPID=; TASession=%1%V2ID.B273D66C4BEC744CE37CDD3CA404F787*SQ.14*LS.Attractions*GR.46*TCPAR.88*TBR.50*EXEX.38*ABTR.30*PPRP.51*PHTB.78*FS.10*CPU.76*HS.popularity*ES.popularity*AS.popularity*DS.5*SAS.popularity*FPS.oldFirst*FA.1*DF.0*LP.%2FLangRedirect%3Fauto%3D3%26origin%3Dzh%26pool%3DX%26returnTo%3D%252FAttractions-g60763-Activities-oa30-New_York_City_New_York%5C.html*IR.3*OD.zh*RT.0*FLO.60763*TRA.true*LD.60763; CM=%1%HanaPersist%2C%2C-1%7Ct4b-pc%2C%2C-1%7CHanaSession%2C%2C-1%7CFtrSess%2C%2C-1%7CRCPers%2C%2C-1%7CHomeAPers%2C%2C-1%7CWShadeSeen%2C%2C-1%7CRCSess%2C%2C-1%7CFtrPers%2C%2C-1%7CHomeASess%2C%2C-1%7Csh%2C%2C-1%7Cpssamex%2C%2C-1%7C2016sticksess%2C%2C-1%7CCCPers%2C%2C-1%7CCCSess%2C%2C-1%7CWAR_RESTAURANT_FOOTER_SESSION%2C%2C-1%7Cb2bmcsess%2C%2C-1%7Csesssticker%2C%2C-1%7C%24%2C%2C-1%7C2016stickpers%2C%2C-1%7Ct4b-sc%2C%2C-1%7CMC_IB_UPSELL_IB_LOGOS2%2C%2C-1%7Cb2bmcpers%2C%2C-1%7CMC_IB_UPSELL_IB_LOGOS%2C%2C-1%7Csess_rev%2C4%2C-1%7Csessamex%2C%2C-1%7CSaveFtrPers%2C%2C-1%7CSaveFtrSess%2C%2C-1%7Cpers_rev%2C%2C-1%7CRBASess%2C%2C-1%7Cperssticker%2C%2C-1%7CMetaFtrSess%2C%2C-1%7Cmds%2C%2C-1%7CRBAPers%2C%2C-1%7CWAR_RESTAURANT_FOOTER_PERSISTANT%2C%2C-1%7CMetaFtrPers%2C%2C-1%7C; TAUD=LA-1465124469834-1*LG-13046557-2.0.F*LD-13046559-.....; TAReturnTo=%1%%2FAttractions-g60763-Activities-oa30-New_York_City_New_York.html'
}
resp = requests.get("http://www.tripadvisor.cn/Attractions-g60763-Activities-oa30-New_York_City_New_York.html#ATTRACTION_LIST",headers=headers)
soup = BeautifulSoup(resp.text,"lxml")
print(soup)
在次查找:

找到了,那我们现在就使用我们调试得到的User-Agent来获取我们想要的内容。
5、加入Referer是否有用?
如:

我们要抓取这个访问量,在网页源码中没找到这个访问量,但是在network中找到了一个api接口:
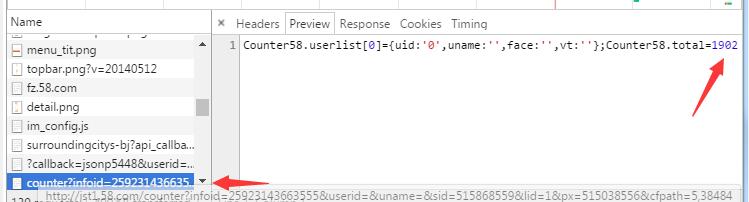
简单分析网址,infoid是我们爬取链接的网页id 在这以为已经成功拿到访问量, 尝试使用程序获取访问量:
得到的结果却是:0

尝试加入Referer。 还是利用类似问题3和问题4的方法,拿到Referer,在headers加入Referer。
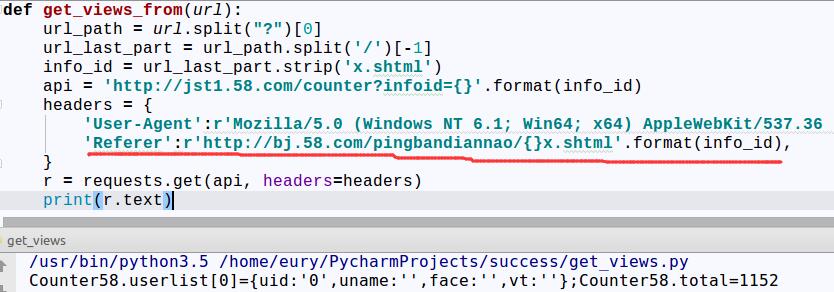
现在已经可以看到我们的访问量啦~
总结一下: 在无法正确拿到数据时,请考虑以下因素:
- 1、selector是否写对?
- 2、网页源码中是否含有我要找的内容?
- 3、在headers中加入Agent-User或者cookie是否有用?
- 4、伪装成手机浏览器是否有用?
- 5、加入Referer是否有用?
- 6、其他