爬虫遇js加载解决办法一
在使用爬虫爬取网页信息时,常常会遇到js脚本加载数据,近而导致无法正确地爬取数据的问题。 在我们的教程中,已经有示范了一个例子,解决办法是使用浏览器伪装成浏览器。 那么现在示范另一种爬虫常用的技巧。 上图:
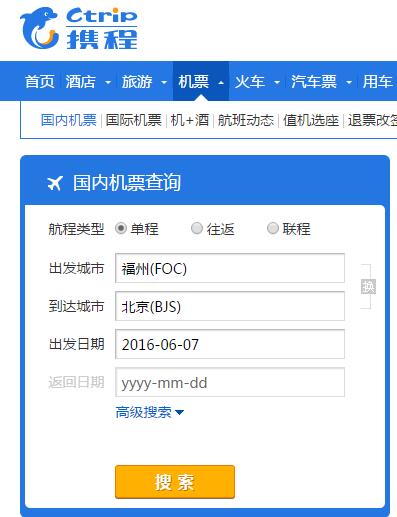
如图,我们如何使用爬虫来进行机票航班的查询呢?首先应该是看看机票查询时是将数据post到哪个网址,如图:
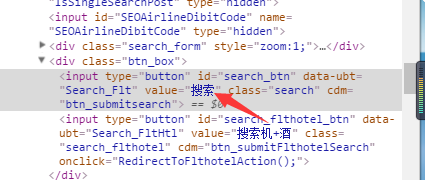
没找到我们想要的网址,这应该是使用js,当我们点击搜索按钮时,js脚本会将数据post上去,近而达到搜索的目的。那现在我们怎么才能知道post的网址呢? 使用开发者工具,按下搜索,来看看网络是如何进行的:
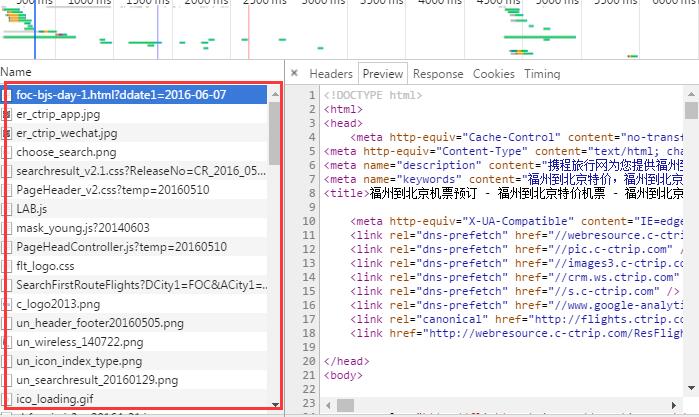
这么多,到底该看哪个呢?
这时我也不知道选谁,那么多,那就看看谁比较适合自己呗。
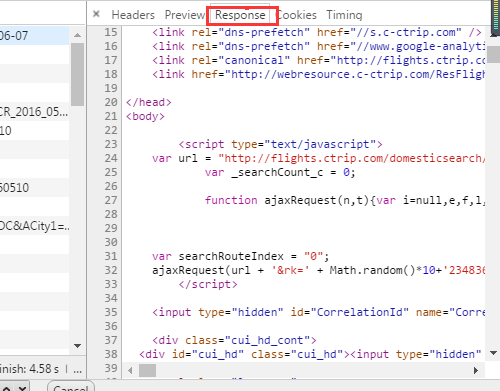
最简单的方法就是把所有的response或者preview都看一遍,这时一般都可以看到你想要的数据。 但是总有不一般的时候,找不到怎么办,想想我们查询的数据有什么,这个数据常常都会出现在url中。那我们也搜索试试。
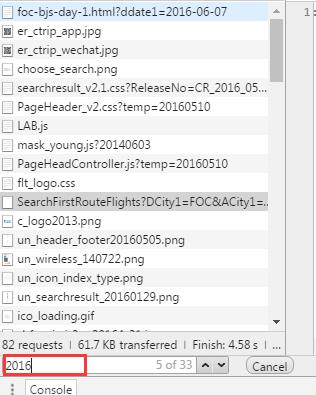
重点看看这几个有2016的数据,ok,找到了

那现在该回到我们最初的原点了 代码如下:
import requests
resp = requests.get("http://flights.ctrip.com/domesticsearch/search/SearchFirstRouteFlights?DCity1=FOC&ACity1=BJS&SearchType=S&DDate1=2016-06-07")
其中DCity1=FOC 代表出发城市,ACity1=BJS 代表目的城市,DDate1=2016-06-07 代表搜索日期。等等
至于该如何处理resp的内容,就根据返回来的内容的格式了,在这不多做解释,有兴趣的可以去研究研究。